Table of Contents
Sakana Fugu Ultra: one API call to a team of frontier LLMs, and whether to switch
Here is the short version: if your agent stack is already wired to a single vendor's API and that vendor could vanish on you, Fugu is the first product that buys back the option cheaply, with a one-line base-URL change. If you mostly run short, single-model calls and you watch every cent, it will cost you more than it saves. The interesting question is which camp you are in, and the answer is more specific than "it depends."
Sakana AI shipped Sakana Fugu and Fugu Ultra on June 22, 2026. Sakana is Japan's most valuable unlisted AI startup, worth over $2.5 billion, per Nikkei Asia. We pulled the release, the third-party benchmark coverage, and the current per-token pricing so you can decide without the launch-day haze. This is a guide for operators currently on Anthropic, OpenAI, or Gemini who are wondering if an orchestration model changes their math.
What an orchestration model actually is
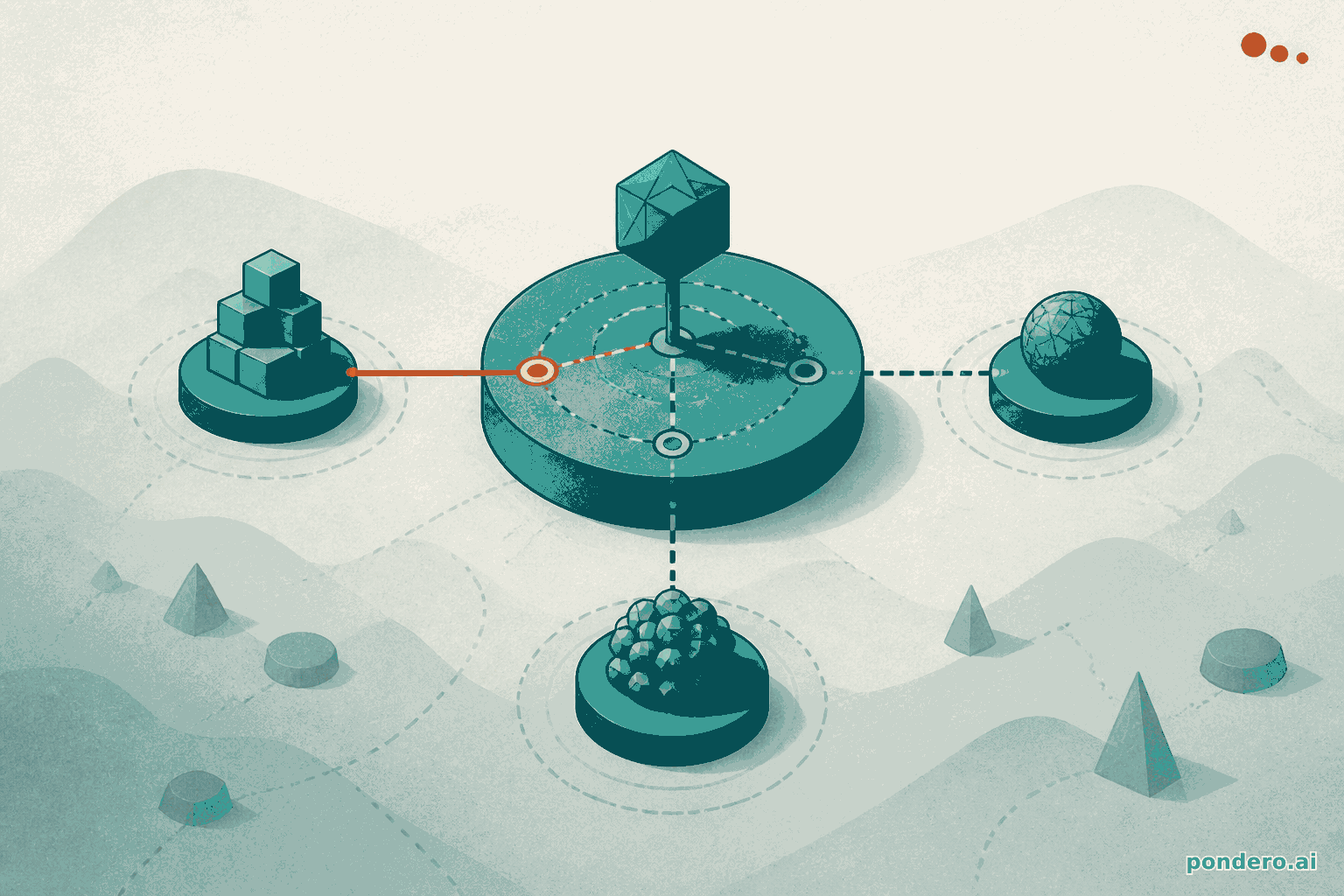
Most models are monoliths. You send a prompt, one giant network answers, done. Fugu is a different shape. It is itself a language model, but it was trained to call other models: it reads your request, decides whether it can answer alone or whether the task needs help, then assembles a small team of expert models, hands them sub-tasks, checks their work, and stitches the results into one reply. Per the Sakana release, model selection, delegation, verification, and synthesis all happen inside the endpoint. Your code never sees the orchestra.
The mental model VentureBeat used is the cleanest one I have read: Fugu behaves like a general contractor. You describe the job, and the contractor decides who to bring in and in what order. Fugu Ultra routes work to 1 to 3 agents depending on the problem, then combines their output, per the Requesty model page. It can even call instances of itself recursively, per MarkTechPost.
The catch, and it is a real one, is that the routing is a black box. Sakana states plainly that which models get picked, and how they are coordinated, is proprietary and hidden from you by design (per VentureBeat). You cannot see that your security-review prompt fanned out to three coders and a verifier. You get the answer and a token bill, nothing in between.

How it differs from a DIY multi-agent setup
If you have ever built a multi-agent system by hand, you know where the time goes. It is not the LLM calls. It is the plumbing: a planner prompt, a router that decides which sub-model handles what, retry logic when an agent returns garbage, a verifier step, and a synthesizer that merges five partial answers without contradicting itself. Then you maintain all of it as models change underneath you.
Fugu's pitch is that the plumbing never reaches your code. The orchestration that you would normally hand-design as a LangGraph or a custom router is learned and baked into the model. Sakana grounds this in two ICLR 2026 papers, Trinity and Conductor, which trained coordinators to assign roles and discover coordination strategies instead of running fixed workflows (per MarkTechPost). You write one chat-completions call. The swarm is somebody else's maintenance burden.
That is the genuine new thing here. A standard multi-agent framework gives you control, observability, and a pile of glue code to own. Fugu gives you none of those, and zero glue code. Whether that trade is good depends entirely on whether you wanted to be in the orchestration business. Most teams shipping a product feature did not.
The skeptics on launch day went straight at this. The dominant Hacker News reaction, per MarkTechPost's review of public sentiment, was "so basically... OpenRouter?" and "how is this not just swapping one single-vendor dependency for another?" Fair questions. The honest distinction: OpenRouter and LiteLLM route your one call to one model you chose. Fugu decides, mid-task, to use several and merges them. It is a router only if you squint. But you are right to notice that you have traded vendor lock-in on Anthropic for vendor lock-in on Sakana's routing logic.
Why the export-controls timing matters
This launch did not happen in a vacuum. On June 12, 2026, the US government's export-control order pushed Anthropic to revoke public access to Claude Fable 5 and Mythos 5, cutting off a broad set of users overnight. If your production agent was calling Fable 5 on June 11, you had a fire drill on June 12.
Sakana built the whole pitch around that fire drill. CEO David Ha framed orchestration as "the practical hedge against this concentration of power," arguing that relying on one company's model for critical infrastructure is a material risk when access can disappear on a policy change (quoted in VentureBeat). The product mechanism backs the rhetoric: because the underlying pool is swappable, if one provider drops out, Fugu routes around it without you touching your code.
One wrinkle for European readers. Fugu is currently restricted from operating inside the EU and EEA while Sakana works to align its black-box routing with GDPR (per VentureBeat). So the tool pitched as the answer to losing access is itself unavailable in a major region today. If you are in Europe, this is a watch-list item, not a deployable one yet.
The benchmarks, and what they actually say
Here is the verified table. Every number below comes from MarkTechPost's reproduction of Sakana's published benchmark grid, where baseline scores are the model providers' own reported figures. Bold marks the top score in each row.
| Benchmark | Fugu Ultra | GPT 5.5 | Gemini 3.1 Pro | Opus 4.8 |
|---|---|---|---|---|
| LiveCodeBench | 93.2 | 85.3 | 88.5 | 87.8 |
| LiveCodeBench Pro | 90.8 | 88.4 | 82.9 | 84.8 |
| SWE Bench Pro | 73.7 | 58.6 | 54.2 | 69.2 |
| TerminalBench 2.1 | 82.1 | 78.2 | 70.3 | 74.6 |
| GPQA-D | 95.5 | 93.6 | 94.3 | 92.0 |
| Humanity's Last Exam | 50.0 | 41.4 | 44.4 | 49.8 |
| Source | MarkTechPost grid |
A few things to read out of this rather than just nod at. Fugu Ultra tops every row in that selection, but the margin is not uniform. On LiveCodeBench it clears the field by 5 to 8 points. On GPQA-D, the graduate-science reasoning test, it is 95.5 versus Opus 4.8's 92.0, a real gap. On Humanity's Last Exam it is 50.0 versus Opus 4.8's 49.8, which is a tie dressed up as a win.
What about Fable 5, the model export controls took away? Anthropic's Fable 5 and Mythos Preview are not in Fugu's pool, since they are not publicly accessible, so Sakana could only compare against published scores. On LiveCodeBench, VentureBeat reports Fugu Ultra at 93.2 against Fable 5's 89.8, and on GPQA-D, Fugu Ultra at 95.5 against Mythos Preview's 94.6. So the headline "matches the restricted models without the restrictions" holds up on the two benchmarks with a head-to-head number.
The thing benchmarks do not show: this is an aggregator beating its own ingredients. Fugu Ultra outscores GPT 5.5 and Gemini 3.1 Pro on coding, and those are exactly the kind of models in its pool. That is the orchestration thesis working. It is also the reason a single model can never match it on a leaderboard and still be the right pick for your workload, which is the next section.
The cost math, done honestly
This is where switching gets real. Fugu Ultra is not cheap.
Per-token, Fugu Ultra runs $5 per million input tokens, $30 per million output, and $0.50 per million cached input, confirmed on both the Requesty model page and VentureBeat. Push past a 272K-token context and those rates double to $10, $45, and $1.00 (per VentureBeat). The context window is 1M tokens with 131K max output (per Requesty).
Put that next to a single frontier model and the output rate is the line that bites. That output rate sits at the premium tier. You are paying an orchestration premium on top of whatever the underlying models would have cost, because behind that one call several models may have run.
For predictable spend, there are subscription tiers (per VentureBeat): a Standard plan at $20/month for lightweight use, Pro at $100/month for 10x the Standard allowance, and Max at $200/month for 20x, aimed at long-running tasks. Sakana has not published the token allowances inside each tier yet, which is a gap worth flagging before you commit a budget. There is a launch sweetener: subscribe to any tier by July 31, 2026 and you get a free second month (per VentureBeat).
The honest read on cost: if your task is one short prompt and one short answer, you are overpaying for an orchestration layer you did not need. If your task is a long, multi-step research or security workflow where a single model would have flailed and burned tokens retrying, the premium can pay for itself by getting to a correct answer in fewer round trips. The break-even is task complexity, not volume.
How to call Fugu from your existing stack
The good news for adoption: there is almost nothing to learn. Fugu speaks the OpenAI chat-completions API, so for most stacks this is a base-URL and model-name change, no SDK migration. Here is the minimal Python call, with the endpoint and key coming from the Sakana console at console.sakana.ai (shape per MarkTechPost).
from openai import OpenAI
# Endpoint and key come from your Sakana console (console.sakana.ai).
client = OpenAI(
base_url="https://<your-fugu-endpoint>/v1", # from console.sakana.ai
api_key="<YOUR_SAKANA_API_KEY>",
)
resp = client.chat.completions.create(
model="fugu-ultra-20260615", # or "fugu" for the low-latency variant
messages=[
{"role": "user",
"content": "Reproduce the method in this paper and report the gap."},
],
)
print(resp.choices[0].message.content)If you would rather not manage the Sakana console directly, Fugu Ultra is also live on aggregator gateways. The Requesty route is a clean drop-in: point base_url at https://router.requesty.ai/v1, set your Requesty key, and set the model to sakana/fugu-ultra (per Requesty). Same three-line change.
from openai import OpenAI
client = OpenAI(
base_url="https://router.requesty.ai/v1",
api_key="<YOUR_REQUESTY_API_KEY>",
)
resp = client.chat.completions.create(
model="sakana/fugu-ultra",
messages=[{"role": "user", "content": "Audit this auth flow for IDOR."}],
)
print(resp.choices[0].message.content)Because it is OpenAI-compatible, Fugu drops straight into a no-code orchestrator too. In n8n, an AI Agent node takes a custom OpenAI-compatible base URL and model string, so you can swap Fugu in behind an existing workflow without rewiring the triggers or the downstream nodes. If you are building research agents on top of Fugu, you will want a web-data layer feeding it clean content, which is where a markdown-extraction API like Firecrawl earns its place in the pipeline. One agent reads the web, Fugu reasons over it.
A practical gotcha to plan for: token usage and cost are reported per request (per MarkTechPost), but which models ran is not. So your observability story is spend, not routing. If your team needs to audit which model touched a regulated prompt, the opt-out controls let you exclude specific providers from the pool, but you still cannot see the per-query selection. Budget for that blind spot before you put Fugu on a compliance-sensitive path.
A self-hosted fallback, for the export-controls crowd
If the reason you are reading this is that a vendor cut you off, do not make Fugu your only plan. The same logic that makes Fugu attractive, no single point of failure, argues against putting all of it on one proprietary router that is itself unavailable in the EU today. The durable hedge is owning a fallback you control: an open-weights model on your own GPU, ready to take traffic when both your primary API and Fugu have a bad day.
Standing that up is mostly an infrastructure exercise. You provision a GPU host, pull an open-weights model, and put it behind the same OpenAI-compatible interface so your router can fail over to it with a base-URL flip. If you do not run your own bare metal, a managed GPU host like Cloudways gets you a provisioned box without the data-center yak-shaving, and you keep the open-weights endpoint as your floor. It will be slower and less capable than Fugu Ultra. That is the point of a floor: it is there on the day nothing else is.
When Fugu is the wrong call
Skip it, or at least do not lead with it, in these cases.
Latency-sensitive paths. Coordinating several models and synthesizing their output takes longer than one model answering directly. For an autocomplete, a fast chat reply, or anything a user is staring at, the regular low-latency Fugu variant exists, but a single fast model is usually the better fit. Fugu Ultra is built for depth, not speed.
Low-volume, simple tasks. If you send a few hundred short prompts a day and each is a one-shot question, the orchestration premium is pure overhead. A mid-tier single model does the job for a fraction of the output cost.
Single-model tasks you have already tuned. If you have a workflow that runs beautifully on one model with a prompt you spent two weeks dialing in, an orchestrator that re-decides the routing on every call removes the very determinism you worked to build. Black-box routing and a tuned pipeline pull in opposite directions.
Anything that needs an audit trail of which model ran. The routing is proprietary and hidden. If a regulator or a customer can ask "which model processed this," Fugu cannot answer that today.
The bottom-line pick
For the operator hedging against vendor lock-in or an export-control cutoff, especially on long, multi-step research, security, or code-review workflows, Fugu Ultra is the most credible ready-to-use option that shipped this month. The benchmarks hold up on the rows that have a head-to-head number, the API change is one line, and the swappable pool is a genuine answer to "what if my vendor disappears." Pair it with a self-hosted open-weights floor so your hedge does not itself become a single point of failure.
For the solo dev or small team running short, latency-sensitive, single-model calls at low volume, stay where you are. The premium output rate and the orchestration overhead will cost you more than the resilience is worth, and you lose the observability and determinism you already have. Keep the base-URL swap in your back pocket and revisit when Sakana publishes the subscription token allowances and opens the EU. The free second month through July 31 makes a trial cheap if you want to watch the routing behave on your own hard tasks first. Just do not migrate a tuned production path on launch-week enthusiasm.